Process & Workflow
FRR is a large project developed by many different groups. This section documents standards for code style & quality, commit messages, pull requests (PRs) and best practices that all contributors are asked to follow.
This chapter is “descriptive/post-factual” in that it documents pratices that are in use; it is not “definitive/pre-factual” in prescribing practices. This means that when a procedure changes, it is agreed upon, then put into practice, and then documented here. If this document doesn’t match reality, it’s the document that needs to be updated, not reality.
Mailing Lists
The FRR development group maintains multiple mailing lists for use by the community. Italicized lists are private.
Topic |
List |
|---|---|
Development |
|
Users & Operators |
|
Announcements |
|
Security |
|
Technical Steering Committee |
The Development list is used to discuss and document general issues related to project development and governance. The public Slack instance and weekly technical meetings provide a higher bandwidth channel for discussions. The results of such discussions must be reflected in updates, as appropriate, to code (i.e., merges), GitHub issues, and for governance or process changes, updates to the Development list and either this file or information posted at https://frrouting.org/.
Development & Release Cycle
Development
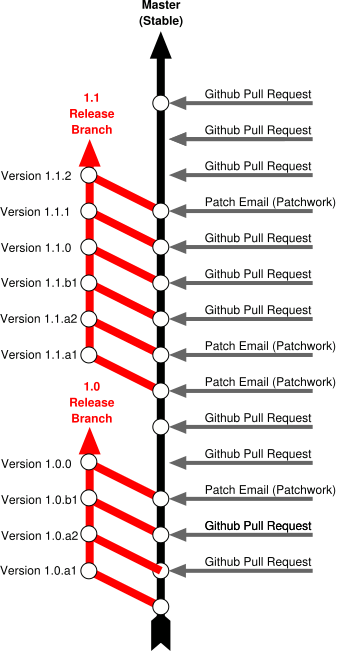
Rough outline of FRR development workflow
The master Git for FRR resides on GitHub.
There is one main branch for development, master. For each major release
(2.0, 3.0 etc) a new release branch is created based on the master. Significant
bugfixes should be backported to upcoming and existing release branches no more
than 1 year old. As a general rule new features are not backported to release
branches.
Subsequent point releases based on a major branch are handled with git tags.
Releases
FRR employs a <MAJOR>.<MINOR>.<BUGFIX> versioning scheme.
MAJORSignificant new features or multiple minor features. This should mostly cover any kind of disruptive change that is visible or “risky” to operators. New features or protocols do not necessarily trigger this. (This was changed for FRR 7.x after feedback from users that the pace of major version number increments was too high.)
MINORGeneral incremental development releases, excluding “major” changes mentioned above. Not necessarily fully backwards compatible, as smaller (but still visible) changes or deprecated feature removals may still happen. However, there shouldn’t be any huge “surprises” between minor releases.
BUGFIXFixes for actual bugs and/or security issues. Fully compatible.
Releases are scheduled in a 4-month cycle on the first Tuesday each March/July/November. Walking backwards from this date:
6 weeks earlier,
masteris frozen for new features, and feature PRs are considered lowest priority (regardless of when they were opened.)4 weeks earlier, the stable branch separates from master (named
dev/MAJOR.MINORat this point) and tagged asbase_X.Y. Master is unfrozen and new features may again proceed.Part of unfreezing master is editing the
AC_INITstatement inconfigure.acto reflect the new development version that master now refers to. This is accompanied by afrr-X.Y.Z-devtag on master, which should always be on the first commit on master after the stable branch was forked (even if that is not the edit toAC_INIT; it’s more important to have it on the very first commit on master after the fork.)(The
configure.acedit and tag push are considered git housekeeping and are pushed directly tomaster, not through a PR.)Below is the snippet of the commands to use in this step.
% git remote --verbose upstream git@github.com:frrouting/frr (fetch) upstream git@github.com:frrouting/frr (push) % git checkout master % git pull upstream master % git checkout -b dev/10.5 % git tag base_10.5 % git push upstream base_10.5 % git push upstream dev/10.5 % git checkout master % sed -i 's/10.4.0-dev/10.5.0-dev/' configure.ac % git add configure.ac % git commit -s -m "build: FRR 10.5.0 development version" % git tag -a frr-10.5.0-dev -m "frr-10.5.0-dev" % git push upstream master % git push upstream frr-10.5.0-devIn this step, we also have to update package versions to reflect the development version. Versions need to be updated using a standard way of development (Pull Requests) based on master branch.
Only change the version number with no other changes. This will produce packages with the a version number that is higher than any previous version. Once the release is done, whatever updates we make to changelog files on the release branch need to be cherry-picked to the master branch.
Update essential dates in advance for reference table (below) when the next freeze, dev/X.Y, RC, and release phases are scheduled. This should go in the
masterbranch.The zebra dataplane API is versioned separately from the FRR release version numbering. Before publishing an FRR release, we need to check the release’s diff in
zebra/zebra_dplane.h. If an incompatible API change is present, increment the major API version and reset the minor and sub-version values to zero. If other changes are present, increment the minor version number.2 weeks earlier, a
frr-X.Y.Z-rcrelease candidate is tagged.% git remote --verbose upstream git@github.com:frrouting/frr (fetch) upstream git@github.com:frrouting/frr (push) % git checkout dev/10.5 % git tag frr-10.5.0-rc % git push upstream frr-10.5.0-rcon release date, the branch is renamed to
stable/MAJOR.MINOR.
The 2 week window between each of these events should be used to run any and all testing possible for the release in progress. However, the current intention is to stick to the schedule even if known issues remain. This would hopefully occur only after all avenues of fixing issues are exhausted, but to achieve this, an as exhaustive as possible list of issues needs to be available as early as possible, i.e. the first 2-week window.
For reference, the expected release schedule according to the above is:
![digraph ReleaseTimeline {
rankdir=LR;
node [shape=box, style=rounded, fontsize=10, width=1.5, fontname="Helvetica"];
subgraph cluster_dev {
label="Development";
style=dashed;
color=blue;
node [fillcolor=lightblue, style=filled];
"dev/X.Y.Z";
}
subgraph cluster_rc {
label="Release Candidate";
style=dashed;
color=orange;
node [fillcolor=orange, style=filled];
"RC";
}
subgraph cluster_stable {
label="Stable Release";
style=dashed;
color=green;
node [fillcolor=lightgreen, style=filled];
"release";
}
// Release steps with actions
"freeze" [label="Freeze", shape=ellipse, style=dotted, fontcolor=red];
"dev/X.Y.Z" [label="dev/X.Y.Z\n(Development)", fillcolor=lightblue];
"RC" [label="RC\n(Release Candidate)", fillcolor=orange];
"release" [label="Release\n(Final)", fillcolor=lightgreen];
// Connect the steps with actions
"freeze" -> "dev/X.Y.Z" [label=" "];
"dev/X.Y.Z" -> "RC" [label=" "];
"RC" -> "release" [label=" "];
// Date connections (freeze -> dev/X.Y.Z -> RC -> release)
"2026-09-22" -> "2026-10-06" -> "2026-10-20" -> "2026-11-03";
"2026-05-26" -> "2026-06-09" -> "2026-06-23" -> "2026-07-07";
"2026-01-20" -> "2026-02-03" -> "2026-02-17" -> "2026-03-03";
"2025-09-23" -> "2025-10-07" -> "2025-10-21" -> "2025-11-04";
}](_images/graphviz-713df81e3780b32eb943f1f8e69391992f350ec1.png)
Here is the hint on how to get the dates easily:
#!/bin/bash # ./release-dates.sh [year] # E.g.: ./release-dates.sh 2026 year="${1:-$(date +%Y)}" first_tuesday() { local year=$1 local month=$2 for day in {1..7}; do weekday=$(date -d "$year-$month-$day" +%u) if [[ $weekday -eq 2 ]]; then date -d "$year-$month-$day" +%Y-%m-%d return fi done } echo "Release Schedule for ${year}" echo "-------------------------" for month in 3 7 11; do release_date=$(first_tuesday "$year" $month) rc_date=$(date -d "$release_date -2 weeks" +%Y-%m-%d) dev_date=$(date -d "$release_date -4 weeks" +%Y-%m-%d) freeze_date=$(date -d "$release_date -6 weeks" +%Y-%m-%d) echo "" echo "Release Month: $(date -d "$release_date" +%B)" echo " Freeze date: $freeze_date" echo " dev/X.Y.Z date: $dev_date" echo " RC date: $rc_date" echo " Release date: $release_date" done
Each release is managed by one or more volunteer release managers from the FRR community. These release managers are expected to handle the branch for a period of one year. To spread and distribute this workload, this should be rotated for subsequent releases. The release managers are currently assumed/expected to run a release management meeting during the weeks listed above. Barring other constraints, this would be scheduled before the regular weekly FRR community call such that important items can be carried over into that call.
Bugfixes are applied to the two most recent releases. It is expected that each bugfix backported should include some reasoning for its inclusion as well as receiving approval by the release managers for that release before accepted into the release branch. This does not necessarily preclude backporting of bug fixes to older than the two most recent releases.
Security fixes are backported to all releases less than or equal to at least one year old. Security fixes may also be backported to older releases depending on severity.
It is important to note that if a fix is backported to stable branch, all newer stable
branches must have that fix too. For example, if a fix is backported to stable/10.0
then all releases after 10.0 are expected to have that fix where applicable.
For detailed instructions on how to produce an FRR release, refer to FRR Release Procedure.
Long term support branches ( LTS )
This kind of branch is not yet officially supported, and need experimentation before being effective.
Previous definition of releases prevents long term support of previous releases. For instance, bug and security fixes are not applied if the stable branch is too old.
Because the FRR users have a need to backport bug and security fixes after the stable branch becomes too old, there is a need to provide support on a long term basis on that stable branch. If that support is applied on that stable branch, then that branch is a long term support branch.
Having a LTS branch requires extra-work and requires one person to be in charge of that maintenance branch for a certain amount of time. The amount of time will be by default set to 4 months, and can be increased. 4 months stands for the time between two releases, this time can be applied to the decision to continue with a LTS release or not. In all cases, that time period will be well-defined and published. Also, a self nomination from a person that proposes to handle the LTS branch is required. The work can be shared by multiple people. In all cases, there must be at least one person that is in charge of the maintenance branch. The person on people responsible for a maintenance branch must be a FRR maintainer. Note that they may choose to abandon support for the maintenance branch at any time. If no one takes over the responsibility of the LTS branch, then the support will be discontinued.
The LTS branch duties are the following ones:
organise meetings on a (bi-)weekly or monthly basis, the handling of issues and pull requests relative to that branch. When time permits, this may be done during the regularly scheduled FRR meeting.
ensure the stability of the branch, by using and eventually adapting the checking the CI tools of FRR ( indeed, maintaining may lead to create maintenance branches for topotests or for CI).
It will not be possible to backport feature requests to LTS branches. Actually, it is a false good idea to use LTS for that need. Introducing feature requests may break the paradigm where all more recent releases should also include the feature request. This would require the LTS maintainer to ensure that all more recent releases have support for this feature request. Moreover, introducing features requests may result in breaking the stability of the branch. LTS branches are first done to bring long term support for stability.
Development Branches
Occasionally the community will desire the ability to work together on a feature that is considered useful to FRR. In this case the parties may ask the Maintainers for the creation of a development branch in the main FRR repository. Requirements for this to happen are:
A one paragraph description of the feature being implemented to allow for the facilitation of discussion about the feature. This might include pointers to relevant RFC’s or presentations that explain what is planned. This is intended to set a somewhat low bar for organization.
A branch maintainer must be named. This person is responsible for keeping the branch up to date, and general communication about the project with the other FRR Maintainers. Additionally this person must already be a FRR Maintainer.
Commits to this branch must follow the normal PR and commit process as outlined in other areas of this document. The goal of this is to prevent the current state where large features are submitted and are so large they are difficult to review.
After a development branch has completed the work together, a final review can be made and the branch merged into master. If a development branch is becomes un-maintained or not being actively worked on after three months then the Maintainers can decide to remove the branch.
Debian Branches
The Debian project contains “official” packages for FRR. While FRR Maintainers may participate in creating these, it is entirely the Debian project’s decision what to ship and how to work on this.
As a courtesy and for FRR’s benefit, this packaging work is currently visible
in git branches named debian/* on the main FRR git repository. These
branches are for the exclusive use by people involved in Debian packaging work
for FRR. Direct commit access may be handed out and FRR git rules (review,
testing, etc.) do not apply. Do not push to these branches without talking
to the people noted under Maintainer: and Uploaders: in
debian/control on the target branch – even if you are a FRR Maintainer.
Changelog
The changelog will be the base for the release notes. A changelog entry for your changes is usually not required and will be added based on your commit messages by the maintainers. However, you are free to include an update to the changelog with some better description.
Accords: non-code community consensus
The FRR repository has a place for “accords” - these are items of
consideration for FRR that influence how we work as a community, but either
haven’t resulted in code yet, or may never result in code being written.
They are placed in the doc/accords/ directory.
The general idea is to simply pass small blurbs of text through our normal PR
procedures, giving them the same visibility, comment and review mechanisms as
code PRs - and changing them later is another PR. Please refer to the README
file in doc/accords/ for further details. The file names of items in that
directory are hopefully helpful in determining whether some of them might be
relevant to your work.
Submitting Patches and Enhancements
FRR accepts patches using GitHub pull requests (PRs). The typical FRR
developer will maintain a fork of the FRR project in GitHub; see the
GitHub documentation for help setting up an account and creating a
fork repository. Keep the master branch of your fork up-to-date
with the FRR version. Create a dev branch in your fork and commit your
work there. When ready, create a pull-request between your dev branch
in your fork and the main FRR repository in GitHub.
The base branch for new contributions and non-critical bug fixes
should be master. Please ensure your pull request targets this
branch when you submit it.
Code submitted by pull request will be automatically tested by one or more CI systems. Once the automated tests succeed, other developers will review your code for quality and correctness. After any concerns are resolved, your code will be merged into the branch it was submitted against.
The title of the pull request should provide a high level technical summary of the included patches. The description should provide additional details that will help the reviewer to understand the context of the included patches.
Squash commits
Before merging make sure a PR has squashed the following kinds of commits:
Fixes/review feedback
Typos
Merges and rebases
Work in progress
This helps to automatically generate human-readable changelog messages.
Commit Guidelines
Commit messages must have a title and optionally a detailed description.
The commit title is a short summary of the commit. The following rules apply:
Must be no more than 72 characters.
Must be prefixed with the name of the changed subsystem, followed by a colon and a space and start with an imperative verb. Check all the supported subsystems.
Should not end with a period.
Should be a complete sentence.
Should “make sense” when used with release changelog.
Think of the end-users reading it and write the title to them.
FRR maintainers should not need to rewrite the message to explain your work to end-users on your behalf.
Example good commit titles:
lib,bgpd: clean up clang warnings babeld: convert all code to use our code formatting rules doc: add commit message guidelines to the dev guide`
The commit description should have more detailed explanation covering also the purpose of the work being done. Formatting guidelines include:
Must be separated from the title by a blank line.
Must be wrapped to 72 characters, unless it is a sample output.
Markdown syntax/output code blocks (3 ticks “```” line before and after).
Write your commit message in the imperative: “Fix bug” and not “Fixed bug” or “Fixes bug.” This convention matches up with commit messages generated by commands like git merge and git revert
Bullet points are okay, too.
Typically a hyphen or asterisk is used for the bullet, followed by a single space. Use a hanging indent.
Example good commit message:
pim6d: support embedded-rp Implement embedded RP support and configuration commands. Embedded RP is disabled by default and can be globally enabled with the command `embedded-rp` in the PIMv6 configuration node. It supports the following options: - Embedded RP maximum limit - Embedded RP group filtering
When opening a PR, please follow the same commit message guidelines above. Also make sure:
If the PR has a single commit, just copy the commit message as-is to the PR, which is the default behavior for a single commit PR on github.
If the PR has more than one commit, add a summary title for the whole PR along with a summary description encompassing all commits.
Make sure that the description you add to the PR is already captured in commits messages. In other words don’t leave the commit messages empty. The PR description should just restate or summaries what the the commit messages already have.
Why was my pull request closed?
Pull requests older than 180 days will be closed. Exceptions can be made for pull requests that have active review comments, or that are awaiting other dependent pull requests. Closed pull requests are easy to recreate, and little work is lost by closing a pull request that subsequently needs to be reopened.
We want to limit the total number of pull requests in flight to:
Maintain a clean project
Remove old pull requests that would be difficult to rebase as the underlying code has changed over time
Encourage code velocity
License for Contributions
FRR is under a “GPLv2 or later” license. Any code submitted must be released under the same license (preferred) or any license which allows redistribution under this GPLv2 license (eg MIT License). It is forbidden to push any code that prevents from using GPLv3 license. This becomes a community rule, as FRR produces binaries that links with Apache 2.0 libraries. Apache 2.0 and GPLv2 license are incompatible, if put together. Please see http://www.apache.org/licenses/GPL-compatibility.html for more information. This rule guarantees the user to distribute FRR binary code without any licensing issues.
Pre-submission Checklist
Format code (see Code Formatting)
Verify and acknowledge license (see License for Contributions)
Ensure you have properly signed off (see Signing Off)
Test building with various configurations:
buildtest.sh
Verify building source distribution:
make dist(and try rebuilding from the resulting tar file)
Run unit tests:
make test
In the case of a major new feature or other significant change, document plans for continued maintenance of the feature. In addition it is a requirement that automated testing must be written that exercises the new feature within our existing CI infrastructure. Also the addition of automated testing to cover any pull request is encouraged.
All new code must use the current latest version of acceptable code.
If a daemon is converted to YANG, then new code must use YANG.
DEFPY’s must be used for new cli
Typesafe lists must be used
printf formatting changes must be used
Signing Off
Code submitted to FRR must be signed off. We have the same requirements for
using the signed-off-by process as the Linux kernel. In short, you must include
a Signed-off-by tag in every patch.
An easy way to do this is to use git commit -s where -s will automatically
append a signed-off line to the end of your commit message. Also, if you commit
and forgot to add the line you can use git commit --amend -s to add the
signed-off line to the last commit.
Signed-off-by is a developer’s certification that they have the right to
submit the patch for inclusion into the project. It is an agreement to the
Developer’s Certificate of Origin.
Code without a proper Signed-off-by line cannot and will not be merged.
The Signed-off-by line must contain your real first name, last name, and a
valid, real email address, in the form:
Signed-off-by: First Last <you@example.com>
Anonymous or pseudonymous sign-offs are not acceptable. In particular,
GitHub’s privacy-protecting noreply addresses (@users.noreply.github.com)
are not allowed: the email address must be a real one at which you can be
reached. Configure your identity accordingly before committing:
git config --global user.name "First Last"
git config --global user.email "you@example.com"
If you are unfamiliar with this process, you should read the official policy at kernel.org. You might also find this article about participating in the Linux community on the Linux Foundation website to be a helpful resource.
In short, when you sign off on a commit, you assert your agreement to all of the following:
Developer's Certificate of Origin 1.1
By making a contribution to this project, I certify that:
(a) The contribution was created in whole or in part by me and I
have the right to submit it under the open source license
indicated in the file; or
(b) The contribution is based upon previous work that, to the best
of my knowledge, is covered under an appropriate open source
license and I have the right under that license to submit that
work with modifications, whether created in whole or in part by
me, under the same open source license (unless I am permitted to
submit under a different license), as indicated in the file; or
(c) The contribution was provided directly to me by some other
person who certified (a), (b) or (c) and I have not modified it.
(d) I understand and agree that this project and the contribution
are public and that a record of the contribution (including all
personal information I submit with it, including my sign-off) is
maintained indefinitely and may be redistributed consistent with
this project or the open source license(s) involved.
After Submitting Your Changes
Watch for Continuous Integration (CI) test results
You should automatically receive an email with the test results within less than 2 hrs of the submission. If you don’t get the email, then check status on the GitHub pull request.
Please notify the development mailing list if you think something doesn’t work.
If the tests failed:
In general, expect the community to ignore the submission until the tests pass.
It is up to you to fix and resubmit.
This includes fixing existing unit (“make test”) tests if your changes broke or changed them.
It also includes fixing distribution packages for the failing platforms (ie if new libraries are required).
Feel free to ask for help on the development list.
Go back to the submission process and repeat until the tests pass.
If the tests pass:
Wait for reviewers. Someone will review your code or be assigned to review your code.
Respond to any comments or concerns the reviewer has. Use e-mail or add a comment via github to respond or to let the reviewer know how their comment or concern is addressed.
An author must never delete or manually dismiss someone else’s comments or review. (A review may be overridden by agreement in the weekly technical meeting.)
When you have addressed someone’s review comments, please click the “re-request review” button (in the top-right corner of the PR page, next to the reviewer’s name, an icon that looks like “reload”)
The responsibility for keeping a PR moving rests with the author at least as long as there are either negative CI results or negative review comments. If you forget to mark a review comment as addressed (by clicking re-request review), the reviewer may very well not notice and won’t come back to your PR.
Automatically generated comments, e.g., those generated by CI systems, may be deleted by authors and others when such comments are not the most recent results from that automated comment source.
After all comments and concerns are addressed, expect your patch to be merged.
Watch out for questions on the mailing list. At this time there will be a manual code review and further (longer) tests by various community members.
Your submission is done once it is merged to the master branch.
Reverting the changes
When you revert a regular commit in Git, the process is straightforward - it undoes the changes introduced by that commit. However, reverting a merge commit is more complex. While it undoes the data changes brought in by the merge, it does not alter the repository’s history or the merge’s effect on it.
Reverting a Merge Commit
When you revert a merge commit, the following occurs:
The changes made by the merge are undone;
The merge itself remains in the history: it continues to be recognized as the point where two branches were joined;
Future merges will still treat this as the last shared state, regardless of the revert.
Thus, a “revert” in Git undoes data changes, but it does not serve as a true “undo” for the historical effects of a commit.
Reverting a Merge and Bisectability
Consider the implications of reverting a merge and then reverting that revert. This scenario complicates the debugging process, especially when using tools like git bisect. A reverted merge effectively consolidates all changes from the original merge into a single commit, but in reverse. This creates a challenge for debugging, as you lose the granularity of individual commits, making it difficult to identify the specific change causing an issue.
Considerations
When reverting the changes, e.g. a full Pull Request, we SHOULD revert every commit individually, and not use git revert on merge commits.
Programming Languages, Tools and Libraries
The core of FRR is written in C (gcc or clang supported) and makes use of GNU compiler extensions. Additionally, the CLI generation tool, clippy, requires Python. A few other non-essential scripts are implemented in Perl and Python. FRR requires the following tools to build distribution packages: automake, autoconf, texinfo, libtool and gawk and various libraries (i.e. libpam and libjson-c).
If your contribution requires a new library or other tool, then please highlight this in your description of the change. Also make sure it’s supported by all FRR platform OSes or provide a way to build without the library (potentially without the new feature) on the other platforms.
Documentation should be written in reStructuredText. Sphinx extensions may be utilized but pure ReST is preferred where possible. See Documentation.
Use of C++
While C++ is not accepted for core components of FRR, extensions, modules or other distinct components may want to use C++ and include FRR header files. There is no requirement on contributors to work to retain C++ compatibility, but fixes for C++ compatibility are welcome.
This implies that the burden of work to keep C++ compatibility is placed with the people who need it, and they may provide it at their leisure to the extent it is useful to them. So, if only a subset of header files, or even parts of a header file are made available to C++, this is perfectly fine.
Code Reviews
Code quality is paramount for any large program. Consequently we require reviews of all submitted patches by at least one person other than the submitter before the patch is merged.
Because of the nature of the software, FRR’s maintainer list (i.e. those with commit permissions) tends to contain employees / members of various organizations. In order to prevent conflicts of interest, we use an honor system in which submissions from an individual representing one company should be merged by someone unaffiliated with that company.
Guidelines for code review
As a rule of thumb, the depth of the review should be proportional to the scope and / or impact of the patch.
Anyone may review a patch.
When using GitHub reviews, marking “Approve” on a code review indicates willingness to merge the PR.
For individuals with merge rights, marking “Changes requested” is equivalent to a NAK.
For a PR you marked with “Changes requested”, please respond to updates in a timely manner to avoid impeding the flow of development.
Rejected or obsolete PRs are generally closed by the submitter based on requests and/or agreement captured in a PR comment. The comment may originate with a reviewer or document agreement reached on Slack, the Development mailing list, or the weekly technical meeting.
Reviewers may ask for new automated testing if they feel that the code change is large enough/significant enough to warrant such a requirement.
For project members with merge permissions, the following patterns have emerged:
a PR with any reviews requesting changes may not be merged.
a PR with any negative CI result may not be merged.
an open “yellow” review mark (“review requested, but not done”) should be given some time (a few days up to weeks, depending on the size of the PR), but is not a merge blocker.
a “textbubble” review mark (“review comments, but not positive/negative”) should be read through but is not a merge blocker.
non-trivial PRs are generally given some time (again depending on the size) for people to mark an interest in reviewing. Trivial PRs may be merged immediately when CI is green.
Coding Practices & Style
Commit messages
Commit messages should be formatted in the same way as Linux kernel commit messages. The format is roughly:
dir: short summary
extended summary
dir should be the top level source directory under which the change was
made. For example, a change in bgpd/rfapi would be formatted as:
bgpd: short summary
...
The first line should be no longer than 50 characters. Subsequent lines should be wrapped to 72 characters.
The purpose of commit messages is to briefly summarize what the commit is changing. Therefore, the extended summary portion should be in the form of an English paragraph. Brief examples of program output are acceptable but if present should be short (on the order of 10 lines) and clearly demonstrate what has changed. The goal should be that someone with only passing familiarity with the code in question can understand what is being changed.
Commit messages consisting entirely of program output are unacceptable. These do not describe the behavior changed. For example, putting VTYSH output or the result of test runs as the sole content of commit messages is unacceptable.
You must also sign off on your commit.
See also
Source File Header
New files must have a copyright header (see License for Contributions above) added to the file. The header should be:
// SPDX-License-Identifier: GPL-2.0-or-later
/*
* Title/Function of file
* Copyright (C) YEAR Author’s Name
*/
#include <zebra.h>
A SPDX-License-Identifier header is required in all source files, i.e.
.c, .h, .cpp and .py files. The license boilerplate should be
removed in these files. Some existing files are missing this header, this is
slowly being fixed.
A SPDX-License-Identifier header and the full license boilerplate is
required in schema definition files, i.e. .yang and .proto. The
rationale for this is that these files are likely to be individually copied to
places outside FRR, and having only the SPDX header would become a “dangling
pointer”.
Warning
DO NOT REMOVE A “Copyright” LINE OR AUTHOR NAME, EVER.
DO NOT APPLY AN SPDX HEADER WHEN THE LICENSE IS UNCLEAR, UNLESS YOU HAVE CHECKED WITH *ALL* SIGNIFICANT AUTHORS.
#include statements and extern "C" {
Due to organic development over about 30 years, #include statements in
the FRR codebase are incredibly inconsistent. There is one strict rule:
The absolute first header included in any C file must be either zebra.h
or config.h (with HAVE_CONFIG_H guard.)
Other than this, the following are “aspirational”:
never use
#include <...>(angle brackets) for headers in FRR’s source tree; it should always be#include "..."exception:
<zebra.h>either acceptable:
"assert.h"/<assert.h>(since this file intentionally replaces a system header with the same name)
use the full path relative to source root, i.e.
#include "lib/if.h"or#include "zebra/rib.h"exception (again):
<zebra.h>exception (again):
"assert.h"/<assert.h>(since this file intentionally replaces a system header with the same name)among the “aspirations” here, this is the most inconsistent across the codebase
the order of includes should be, with a blank line in between each group:
(source files only:)
<zebra.h>or"config.h"system includes, e.g.
<stdint.h>includes from FRR’s library, e.g.
"lib/if.h"includes from the daemon, e.g.
"zebra/rib.h"(headers only:)
extern "C" {- never place this before an#includestatement(headers only:) forward declarations of structs, e.g.
struct interface;
Note that the
extern "C"block is only necessary for headers that might be used from C++ code, i.e. primarily files inlib/andzebra/.zebra.h(orconfig.h) should only be included from.cfiles, not from headers. One of them is required to be the first include anyway.do not add FRR-specific declarations/definitions to
zebra.h. That file is intended primarily as an “include multiplexer” for system header files. The fact that it currently contains FRR specific bits is a bug, not a feature, and might hopefully get tackled at some point.The function of
zebra.his similar to a PCH (pre-compiled header), except investigation has shown no real build time benefit from actually using it as a PCH, so it was never integrated into the build as such.in header files, if struct forward declarations can be used to replace
#includestatements, that is preferable.self-reliancy for header files (e.g. having them include everything they use) is appreciated.
Adding Copyright Claims to Existing Files
When adding copyright claims for modifications to an existing file, please
add a Portions: section as shown below. If this section already exists, add
your new claim at the end of the list.
/*
* Title/Function of file
* Copyright (C) YEAR Author’s Name
* Portions:
* Copyright (C) 2010 Entity A ....
* Copyright (C) 2016 Your name [optional brief change description]
* ...
*/
Defensive coding requirements
In general, code submitted into FRR will be rejected if it uses unsafe programming practices. While there is no enforced overall ruleset, the following requirements have achieved consensus:
strcpy,strcatandsprintfare unacceptable without exception. Usestrlcpy,strlcatandsnprintfinstead. (Rationale: even if you know the operation cannot overflow the buffer, a future code change may inadvertently introduce an overflow.)buffer size arguments, particularly to
strlcpyandsnprintf, must usesizeof()wherever possible. Particularly, do not use a size constant in these cases. (Rationale: changing a buffer to another size constant may leave the write operations on a now-incorrect size limit.)For stack allocated structs and arrays that should be zero initialized, prefer initializer expressions over
memset()wherever possible. This helps preventmemset()calls being missed in branches, and eliminates the error class of an incorrectsizeargument tomemset().For example, instead of:
struct foo mystruct; ... memset(&mystruct, 0x00, sizeof(struct foo));
Prefer:
struct foo mystruct = {};
Do not zero initialize stack allocated values that must be initialized with a nonzero value in order to be used. This way the compiler and memory checking tools can catch uninitialized value use that would otherwise be suppressed by the (incorrect) zero initialization.
Usage of
system()or other c library routines that cause signals to possibly be ignored are not allowed. This includes thefork()andexecXXcall patterns, which is actually what system() does underneath the covers. This pattern causes the system shutdown to never work properly as the SIGINT sent is never received. It is better to just prohibit code that does this instead of having to debug shutdown issues again.
Other than these specific rules, coding practices from the Linux kernel as well as CERT or MISRA C guidelines may provide useful input on safe C code. However, these rules are not applied as-is; some of them expressly collide with established practice.
Container implementations
In particular to gain defensive coding benefits from better compiler type
checks, there is a set of replacement container data structures to be found
in lib/typesafe.h. They’re documented under Type-safe containers.
Unfortunately, the FRR codebase is quite large, and migrating existing code to use these new structures is a tedious and far-reaching process (even if it can be automated with coccinelle, the patches would touch whole swaths of code and create tons of merge conflicts for ongoing work.) Therefore, little existing code has been migrated.
However, both new code and refactors of existing code should use the new containers. If there are any reasons this can’t be done, please work to remove these reasons (e.g. by adding necessary features to the new containers) rather than falling back to the old code.
In order of likelihood of removal, these are the old containers:
nhrpd/list.*,hlist_*⇒DECLARE_LISTnhrpd/list.*,list_*⇒DECLARE_DLISTlib/skiplist.*,skiplist_*⇒DECLARE_SKIPLISTlib/*_queue.h(BSD),SLIST_*⇒DECLARE_LISTlib/*_queue.h(BSD),LIST_*⇒DECLARE_DLISTlib/*_queue.h(BSD),STAILQ_*⇒DECLARE_LISTlib/*_queue.h(BSD),TAILQ_*⇒DECLARE_DLISTlib/hash.*,hash_*⇒DECLARE_HASHlib/linklist.*,list_*⇒DECLARE_DLISTopen-coded linked lists ⇒
DECLARE_LIST/DECLARE_DLIST
Code Formatting
C Code
For C code, FRR uses Linux kernel style except where noted below. Code which does not comply with these style guidelines will not be accepted.
The project provides multiple tools to allow you to correctly style your code
as painlessly as possible, primarily built around clang-format.
clang-format
In the project root there is a
.clang-formatconfiguration file which can be used with theclang-formatsource formatter tool from the LLVM project. Most of the time, this is the easiest and smartest tool to use. It can be run in a variety of ways. If you point it at a C source file or directory of source files, it will format all of them. In the LLVM source tree there are scripts that allow you to integrate it withgit,vimandemacs, and there are third-party plugins for other editors. Thegitintegration is particularly useful; suppose you have some changes in your git index. Then, with the integration installed, you can do the following:git clang-formatThis will format only the changes present in your index. If you have just made a few commits and would like to correctly style only the changes made in those commits, you can use the following syntax:
git clang-format HEAD~XWhere X is one more than the number of commits back from the tip of your branch you would like
clang-formatto look at (similar to specifying the target for a rebase).The
vimplugin is particularly useful. It allows you to select lines in visual line mode and press a key binding to invokeclang-formaton only those lines.When using
clang-format, it is recommended to use the latest version. Each consecutive version generally has better handling of various edge cases. You may notice on occasion that two consecutive runs ofclang-formatover the same code may result in changes being made on the second run. This is an unfortunate artifact of the tool. Please check with the kernel style guide if in doubt.One stylistic problem with the FRR codebase is the use of
DEFUNmacros for defining CLI commands.clang-formatwill happily format these macro invocations, but the result is often unsightly and difficult to read. Consequently, FRR takes a more relaxed position with how these are formatted. In general you should lean towards using the style exemplified in the section on Command Line Interface. Becauseclang-formatmangles this style, there is a Python script namedtools/indent.pythat wrapsclang-formatand handlesDEFUNmacros as well as some other edge cases specific to FRR. If you are submitting a new file, it is recommended to run that script over the new file, preferably after ensuring that the latest stable release ofclang-formatis in yourPATH.Documentation on
clang-formatand its various integrations is maintained on the LLVM website.
checkpatch.sh checkpatch.pl
See also
In the Linux kernel source tree there is a Perl script used to check incoming patches for style errors. FRR uses a shell script front end and an adapted version of the perl script for the same purpose. These scripts can be found at
tools/checkpatch.shandtools/checkpatch.pl. This script takes a git-formatted diff or patch file, applies it to a clean FRR tree, and inspects the result to catch potential style errors. Running this script on your patches before submission is highly recommended. The CI system runs this script as well and will comment on the PR with the results if style errors are found.It is run like this:
./checkpatch.sh <patch> <tree>Reports are generated on
stderrand the exit code indicates whether issues were found (2, 1) or not (0).Where
<patch>is the path to the diff or patch file and<tree>is the path to your FRR source tree. The tree should be on the branch that you intend to submit the patch against. The script will make a best-effort attempt to save the state of your working tree and index before applying the patch, and to restore it when it is done, but it is still recommended that you have a clean working tree as the script does perform a hard reset on your tree during its run.The script reports two classes of issues, namely WARNINGs and ERRORs. Please pay attention to both of them. The script will generally report WARNINGs where it cannot be 100% sure that a particular issue is real. In most cases WARNINGs indicate an issue that needs to be fixed. Sometimes the script will report false positives; these will be handled in code review on a case-by-case basis. Since the script only looks at changed lines, occasionally changing one part of a line can cause the script to report a style issue already present on that line that is unrelated to the change. When convenient it is preferred that these be cleaned up inline, but this is not required.
In general, a developer should heed the information reported by checkpatch. However, some flexibility is needed for cases where human judgement yields better clarity than the script. Accordingly, it may be appropriate to ignore some checkpatch.sh warnings per discussion among the submitter(s) and reviewer(s) of a change. Misreporting of errors by the script is possible. When this occurs, the exception should be handled either by patching checkpatch to correct the false error report, or by documenting the exception in this document under Exceptions. If the incorrect report is likely to appear again, a checkpatch update is preferred.
If the script finds one or more WARNINGs it will exit with 1. If it finds one or more ERRORs it will exit with 2.
For convenience the Linux documentation for the
tools/checkpatch.plscript has been included unmodified (i.e., it has not been updated to reflect local changes) here
Please remember that while FRR provides these tools for your convenience, responsibility for properly formatting your code ultimately lies on the shoulders of the submitter. As such, it is recommended to double-check the results of these tools to avoid delays in merging your submission.
In some cases, these tools modify or flag the format in ways that go beyond or even conflict [1] with the canonical documented Linux kernel style. In these cases, the Linux kernel style takes priority; non-canonical issues flagged by the tools are not compulsory but rather are opportunities for discussion among the submitter(s) and reviewer(s) of a change.
Whitespace changes in untouched parts of the code are not acceptable in patches that change actual code. To change/fix formatting issues, please create a separate patch that only does formatting changes and nothing else.
Kernel and BSD styles are documented externally:
For GNU coding style, use indent with the following invocation:
indent -nut -nfc1 file_for_submission.c
Historically, FRR used fixed-width integral types that do not exist in any
standard but were defined by most platforms at some point. Officially these
types are not guaranteed to exist. Therefore, please use the fixed-width
integral types introduced in the C99 standard when contributing new code to
FRR. If you need to convert a large amount of code to use the correct types,
there is a shell script in tools/convert-fixedwidth.sh that will do the
necessary replacements.
Incorrect |
Correct |
|---|---|
u_int8_t |
uint8_t |
u_int16_t |
uint16_t |
u_int32_t |
uint32_t |
u_int64_t |
uint64_t |
u_char |
uint8_t or unsigned char |
u_short |
unsigned short |
u_int |
unsigned int |
u_long |
unsigned long |
FRR also uses unnamed struct fields, enabled with -fms-extensions (cf.
https://gcc.gnu.org/onlinedocs/gcc/Unnamed-Fields.html). The following two
patterns can/should be used where contextually appropriate:
struct outer {
struct inner;
};
struct outer {
union {
struct inner;
struct inner inner_name;
};
};
Exceptions
FRR project code comes from a variety of sources, so there are some stylistic exceptions in place. They are organized here by branch.
For master:
BSD coding style applies to:
ldpd/
babeld uses, approximately, the following style:
K&R style braces
Indents are 4 spaces
Function return types are on their own line
For stable/3.0 and stable/2.0:
GNU coding style apply to the following parts:
lib/zebra/bgpd/ospfd/ospf6d/isisd/ripd/ripngd/vtysh/
BSD coding style applies to:
ldpd/
Python Code
Format all Python code with black.
In a line:
python3 -m black <file.py>
Run this on any Python files you modify before committing.
FRR’s Python code has been formatted with black version 19.10b.
YANG
FRR uses YANG to define data models for its northbound interface. YANG models
should follow conventions used by the IETF standard models. From a practical
standpoint, this corresponds to the output produced by the yanglint tool
included in the libyang project, which is used by FRR to parse and validate
YANG models. You should run the following command on all YANG documents you
write:
yanglint -f yang <model>
The output of this command should be identical to the input file. The sole
exception to this is comments. yanglint does not support comments and will
strip them from its output. You may include comments in your YANG documents,
but they should be indented appropriately (use spaces). Where possible,
comments should be eschewed in favor of a suitable description statement.
In short, a diff between your input file and the output of yanglint should
either be empty or contain only comments.
Specific Exceptions
Most of the time checkpatch errors should be corrected. Occasionally as a group maintainers will decide to ignore certain stylistic issues. Usually this is because correcting the issue is not possible without large unrelated code changes. When an exception is made, if it is unlikely to show up again and doesn’t warrant an update to checkpatch, it is documented here.
Issue |
Ignore Reason |
|---|---|
DEFPY_HIDDEN, DEFPY_ATTR: complex macros should be wrapped in parentheses |
DEF* macros cannot be wrapped in parentheses without updating all usages of the macro, which would be highly disruptive. |
Types of configurables
Note
This entire section essentially just argues to not make configuration unnecessarily involved for the user. Rather than rules, this is more of a list of conclusions intended to help make FRR usable for operators.
Almost every feature FRR has comes with its own set of switches and options. There are several stages at which configuration can be applied. In order of preference, these are:
at configuration/runtime, through YANG.
This is the preferred way for all FRR knobs. Not all daemons and features are fully YANGified yet, so in some cases new features cannot rely on a YANG interface. If a daemon already implements a YANG interface (even partial), new CLI options must be implemented through a YANG model.
Warning
Unlike everything else in this section being guidelines with some slack, implementing and using a YANG interface for new CLI options in (even partially!) YANGified daemons is a hard requirement.
at configuration/runtime, through the CLI.
The “good old” way for all regular configuration. More involved for users to automate correctly than YANG.
at startup, by loading additional modules.
If a feature introduces a dependency on additional libraries (e.g. libsnmp, rtrlib, etc.), this is the best way to encapsulate the dependency. Having a separate module allows the distribution to create a separate package with the extra dependency, so FRR can still be installed without pulling everything in.
A module may also be appropriate if a feature is large and reasonably well isolated. Reducing the amount of running the code is a security benefit, so even if there are no new external dependencies, modules can be useful.
While modules cannot currently be loaded at runtime, this is a tradeoff decision that was made to allow modules to change/extend code that is very hard to (re)adjust at runtime. If there is a case for runtime (un)loading of modules, this tradeoff can absolutely be reevaluated.
at startup, with command line options.
This interface is only appropriate for options that have an effect very early in FRR startup, i.e. before configuration is loaded. Anything that affects configuration load itself should be here, as well as options changing the environment FRR runs in.
If a tunable can be changed at runtime, a command line option is only acceptable if the configured value has an effect before configuration is loaded (e.g. zebra reads routes from the kernel before loading config, so the netlink buffer size is an appropriate command line option.)
at compile time, with
./configureoptions.This is the absolute last preference for tunables, since the distribution needs to make the decision for the user and/or the user needs to rebuild FRR in order to change the option.
“Good” configure options do one of three things:
set distribution-specific parameters, most prominently all the path options. File system layout is a distribution/packaging choice, so the user would hopefully never need to adjust these.
changing toolchain behavior, e.g. instrumentation, warnings, optimizations and sanitizers.
enabling/disabling parts of the build, especially if they need additional dependencies. Being able to build only parts of FRR, or without some library, is useful. The only effect these options should have is adding or removing files from the build result. If a knob in this category causes the same binary to exist in different variants, it is likely implemented incorrectly!
Note
This last guideline is currently ignored by several configure options.
vtyshin general depends on the entire list of enabled daemons, and options like--enable-bgp-vncand--enable-ospfapichange daemons internally. Consider this more of an “ideal” than a “rule”.
Whenever adding new knobs, please try reasonably hard to go up as far as
possible on the above list. Especially ./configure flags are often enough
the “easy way out” but should be avoided when at all possible. To a lesser
degree, the same applies to command line options.
Compile-time conditional code
Many users access FRR via binary packages from 3rd party sources;
compile-time code puts inclusion/exclusion in the hands of the package
maintainer. Please think very carefully before making code conditional
at compile time, as it increases regression testing, maintenance
burdens, and user confusion. In particular, please avoid gratuitous
--enable-… switches to the configure script - in general, code
should be of high quality and in working condition, or it shouldn’t be
in FRR at all.
When code must be compile-time conditional, try have the compiler make it conditional rather than the C pre-processor so that it will still be checked by the compiler, even if disabled. For example,
if (SOME_SYMBOL)
frobnicate();
is preferred to
#ifdef SOME_SYMBOL
frobnicate ();
#endif /* SOME_SYMBOL */
Note that the former approach requires ensuring that SOME_SYMBOL will be
defined (watch your AC_DEFINEs).
Debug-guards in code
Debugging statements are an important methodology to allow developers to fix issues found in the code after it has been released. The caveat here is that the developer must remember that people will be using the code at scale and in ways that can be unexpected for the original implementor. As such debugs MUST be guarded in such a way that they can be turned off. FRR has the ability to turn on/off debugs from the CLI and it is expected that the developer will use this convention to allow control of their debugs.
Custom syntax-like block macros
FRR uses some macros that behave like the for or if C keywords. These
macros follow these patterns:
loop-style macros are named
frr_each_*(andfrr_each)single run macros are named
frr_with_*to avoid confusion,
frr_with_*macros must always use a{ ... }block even if the block only contains one statement. Thefrr_eachconstructs are assumed to be well-known enough to use normalforrules.break,returnandgotoall work correctly. For loop-style macros,continueworks correctly too.
Both the each and with keywords are inspired by other (more
higher-level) programming languages that provide these constructs.
There are also some older iteration macros, e.g. ALL_LIST_ELEMENTS and
FOREACH_AFI_SAFI. These macros in some cases do not fulfill the above
pattern (e.g. break does not work in FOREACH_AFI_SAFI because it
expands to 2 nested loops.)
Static Analysis and Sanitizers
Clang/LLVM and GCC come with a variety of tools that can be used to help find bugs in FRR.
- clang-analyze
This is a static analyzer that scans the source code looking for patterns that are likely to be bugs. The tool is run automatically on pull requests as part of CI and new static analysis warnings will be placed in the CI results. FRR aims for absolutely zero static analysis errors. While the project is not quite there, code that introduces new static analysis errors is very unlikely to be merged.
- AddressSanitizer
This is an excellent tool that provides runtime instrumentation for detecting memory errors. As part of CI FRR is built with this instrumentation and run through a series of tests to look for any results. Testing your own code with this tool before submission is encouraged. You can enable it by passing:
--enable-address-sanitizer
to
configure.- ThreadSanitizer
Similar to AddressSanitizer, this tool provides runtime instrumentation for detecting data races. If you are working on or around multithreaded code, extensive testing with this instrumtation enabled is highly recommended. You can enable it by passing:
--enable-thread-sanitizer
to
configure.- MemorySanitizer
Similar to AddressSanitizer, this tool provides runtime instrumentation for detecting use of uninitialized heap memory. Testing your own code with this tool before submission is encouraged. You can enable it by passing:
--enable-memory-sanitizer
to
configure.- UndefinedSanitizer
Similar to AddressSanitizer, this tool provides runtime instrumentation for detecting use of undefined behavior in C. Testing your own code with this tool before submission is encouraged. You can enable it by passing:
--enable-undefined-sanitizer to ``configure``. If you run FRR with this you will probably also have to set ``sudo sysctl vm.mmap_rnd_bits=28``
All of the above tools are available in the Clang/LLVM toolchain since 3.4. AddressSanitizer and ThreadSanitizer are available in recent versions of GCC, but are no longer actively maintained. MemorySanitizer is not available in GCC.
Note
The different Sanitizers are mostly incompatible with each other. Please refer to GCC/LLVM documentation for details.
Note
The different sanitizers also require setting
sysctl vm.mmap_rnd_bits=28
in order to work properly.
- frr-format plugin
This is a GCC plugin provided with FRR that does extended type checks for
%pFX-style printfrr extensions. To use this plugin,install GCC plugin development files, e.g.:
apt-get install gcc-10-plugin-dev
before running
configure, compile the plugin with:make -C tools/gcc-plugins CXX=g++-10
(Edit the GCC version to what you’re using, it should work for GCC 9 or newer.)
After this, the plugin should be automatically picked up by
configure. The plugin does not change very frequently, so you can keep it around across work on different FRR branches. After agit clean -x, themakeline will need to be run again. You can also add--with-frr-formatto theconfigureline to make sure the plugin is used, otherwise if something is not set up correctly it might be silently ignored.Warning
Do not enable this plugin for package/release builds. It is intended for developer/debug builds only. Since it modifies the compiler, it may cause silent corruption of the executable files.
Using the plugin also changes the string for
PRI[udx]64from the system value to%L[udx](normally%ll[udx]or%l[udx].)
Additionally, the FRR codebase is regularly scanned for static analysis
errors with Coverity and pull request changes are scanned as part of the
Continuous Integration (CI) process. Developers can scan their commits for
Coverity static analysis errors prior to submission using the
scan-build command. To use this command, the clang-tools package must
be installed. For example, this can be accomplished on Ubuntu with the
sudo apt-get install clang-tools command. Then, touch the files you want scanned and
invoke the scan-build command. For example:
cd ~/GitHub/frr
touch ospfd/ospf_flood.c ospfd/ospf_vty.c ospfd/ospf_opaque.c
cd build
scan-build make -j32
The results of the scan including any static analysis errors will appear inline. Additionally, there will a directory in the /tmp containing the Coverity reports (e.g., scan-build-2023-06-09-120100-473730-1).
Executing non-installed dynamic binaries
Since FRR uses the GNU autotools build system, it inherits its shortcomings. To execute a binary directly from the build tree under a wrapper like valgrind, gdb or strace, use:
./libtool --mode=execute valgrind [--valgrind-opts] zebra/zebra [--zebra-opts]
While replacing valgrind/zebra as needed. The libtool script is found in the root of the build directory after ./configure has completed. Its purpose is to correctly set up LD_LIBRARY_PATH so that libraries from the build tree are used. (On some systems, libtool is also available from PATH, but this is not always the case.)
CLI changes
CLI’s are a complicated ugly beast. Additions or changes to the CLI should use a DEFPY to encapsulate one setting as much as is possible. Additionally as new DEFPY’s are added to the system, documentation should be provided for the new commands.
Backwards Compatibility
As a general principle, changes to CLI and code in the lib/ directory should be made in a backwards compatible fashion. This means that changes that are purely stylistic in nature should be avoided, e.g., renaming an existing macro or library function name without any functional change. When adding new parameters to common functions, it is also good to consider if this too should be done in a backward compatible fashion, e.g., by preserving the old form in addition to adding the new form.
This is not to say that minor or even major functional changes to CLI and common code should be avoided, but rather that the benefit gained from a change should be weighed against the added cost/complexity to existing code. Also, that when making such changes, it is good to preserve compatibility when possible to do so without introducing maintenance overhead/cost. It is also important to keep in mind, existing code includes code that may reside in private repositories (and is yet to be submitted) or code that has yet to be migrated from Quagga to FRR.
That said, compatibility measures can (and should) be removed when either:
they become a significant burden, e.g. when data structures change and the compatibility measure would need a complex adaptation layer or becomes flat-out impossible
some measure of time (dependent on the specific case) has passed, so that the compatibility grace period is considered expired.
For CLI commands, the deprecation period is 1 year.
In all cases, compatibility pieces should be marked with compiler/preprocessor
annotations to print warnings at compile time, pointing to the appropriate
update path. A -Werror build should fail if compatibility bits are used. To
avoid compilation issues in released code, such compiler/preprocessor
annotations must be ignored non-development branches. For example:
#if CONFDATE > 20180403
CPP_NOTICE("Use of <XYZ> is deprecated, please use <ABC>")
#endif
Preferably, the shell script tools/fixup-deprecated.py will be
updated along with making non-backwards compatible code changes, or an
alternate script should be introduced, to update the code to match the
change. When the script is updated, there is no need to preserve the
deprecated code. Note that this does not apply to user interface
changes, just internal code, macros and libraries.
Miscellaneous
When in doubt, follow the guidelines in the Linux kernel style guide, or ask on the development mailing list / public Slack instance.
JSON Output
New JSON output in FRR needs to be backed by schema, in particular a YANG model. When adding new JSON, first search for an existing YANG model, either in FRR or a standard model (e.g., IETF) and use that model as the basis for any JSON structure and especially for key names and canonical values formats.
If no YANG model exists to support the JSON then an FRR YANG model needs to be added to or created to support the JSON format.
All JSON keys are to be
camelCased, with no spaces. YANG modules almost always usekebab-case(i.e., all lower case with hyphens to separate words), so these identifiers need to be mapped tocamelCaseby removing the hyphen (or symbol) and capitalizing the following letter, for example “router-id” becomes “routerId”Commands which output JSON should produce
{}if they have nothing to display or if an error occurs with the input.In general JSON commands include a
jsonkeyword typically at the end of the CLI command (e.g.,show ip ospf json)
Use of const
Please consider using const when possible: it’s a useful hint to
callers about the limits to side-effects from your apis, and it makes
it possible to use your apis in paths that involve const
objects. If you encounter existing apis that could be const,
consider including changes in your own pull-request.
Help with specific warnings
FRR’s configure script enables a whole batch of extra warnings, some of which may not be obvious in how to fix. Here are some notes on specific warnings:
-Wstrict-prototypes: you probably just forgot thevoidin a function declaration with no parameters, i.e.static void foo() {...}rather thanstatic void foo(void) {...}.Without the
void, in C, it’s a function with unspecified parameters (and varargs calling convention.) This is a notable difference to C++, where thevoidis optional and an empty parameter list means no parameters."strict match required"from the frr-format plugin: check if you are using a cast in a printf parameter list. The frr-format plugin cannot access correct full type information for casts likeprintfrr(..., (uint64_t)something, ...)and will print incorrect warnings particularly ifuint64_t,size_torptrdiff_tare involved. The problem is not triggered with a variable or function return value of the exact same type (without a cast).Since these cases are very rare, community consensus is to just work around the warning even though the code might be correct. If you are running into this, your options are:
try to avoid the cast altogether, maybe using a different printf format specifier (e.g.
%luinstead of%zuorPRIu64).fix the type(s) of the function/variable/struct member being printed
create a temporary variable with the value and print that without a cast (this is the last resort and was not necessary anywhere so far.)
Documentation
FRR uses Sphinx+RST as its documentation system. The document you are currently
reading was generated by Sphinx from RST source in
doc/developer/workflow.rst. The documentation is structured as follows:
Directory |
Contents |
|---|---|
|
User documentation; configuration guides; protocol overviews |
|
Developer’s documentation; API specs; datastructures; architecture overviews; project management procedure |
|
Source for manpages |
|
Images and diagrams |
|
Miscellaneous Sphinx extensions, scripts, customizations, etc. |
Each of these directories, with the exception of doc/figures and
doc/extra, contains a Sphinx-generated Makefile and configuration
script conf.py used to set various document parameters. The makefile
can be used for a variety of targets; invoke make help in any of these
directories for a listing of available output formats. For convenience, there
is a top-level Makefile.am that has targets for PDF and HTML
documentation for both developer and user documentation, respectively. That
makefile is also responsible for building manual pages packed with distribution
builds.
Indent and styling should follow existing conventions:
3 spaces for indents under directives
Cross references may contain only lowercase alphanumeric characters and hyphens (‘-‘)
Lines wrapped to 80 characters where possible
Characters for header levels should follow Python documentation guide:
#with overline, for parts*with overline, for chapters=, for sections-, for subsections^, for subsubsections", for paragraphs
After you have made your changes, please make sure that you can invoke
make latexpdf and make html with no warnings.
The documentation is currently incomplete and needs love. If you find a broken cross-reference, figure, dead hyperlink, style issue or any other nastiness we gladly accept documentation patches.
To build the docs, please ensure you have installed a recent version of Sphinx. If you want to build LaTeX or PDF docs, you will also need a full LaTeX distribution installed.
Code
FRR is a large and complex software project developed by many different people over a long period of time. Without adequate documentation, it can be exceedingly difficult to understand code segments, APIs and other interfaces. In the interest of keeping the project healthy and maintainable, you should make every effort to document your code so that other people can understand what it does without needing to closely read the code itself.
Some specific guidelines that contributors should follow are:
Functions exposed in header files should have descriptive comments above their signatures in the header file. At a minimum, a function comment should contain information about the return value, parameters, and a general summary of the function’s purpose. Documentation on parameter values can be omitted if it is (very) obvious what they are used for.
Function comments must follow the style for multiline comments laid out in the kernel style guide.
Example:
/* * Determines whether or not a string is cool. * * text * the string to check for coolness * * is_clccfc * whether capslock is cruise control for cool * * Returns: * 7 if the text is cool, 0 otherwise */ int check_coolness(const char *text, bool is_clccfc);
Function comments should make it clear what parameters and return values are used for.
Static functions should have descriptive comments in the same form as above if what they do is not immediately obvious. Use good engineering judgement when deciding whether a comment is necessary. If you are unsure, document your code.
Global variables, static or not, should have a comment describing their use.
For new code in lib/, these guidelines are hard requirements.
If you make significant changes to portions of the codebase covered in the Developer’s Manual, add a major subsystem or feature, or gain arcane mastery of some undocumented or poorly documented part of the codebase, please document your work so others can benefit. If you add a major feature or introduce a new API, please document the architecture and API to the best of your abilities in the Developer’s Manual, using good judgement when choosing where to place it.
Finally, if you come across some code that is undocumented and feel like going above and beyond, document it! We absolutely appreciate and accept patches that document previously undocumented code.
User
If you are contributing code that adds significant user-visible functionality
please document how to use it in doc/user. Use good judgement when
choosing where to place documentation. For example, instructions on how to use
your implementation of a new BGP draft should go in the BGP chapter instead of
being its own chapter. If you are adding a new protocol daemon, please create a
new chapter.
FRR Specific Markup
FRR has some customizations applied to the Sphinx markup that go a long way towards making documentation easier to use, write and maintain.
CLI Commands
When documenting CLI please use the .. clicmd:: directive. This directive
will format the command and generate index entries automatically. For example,
the command show pony would be documented as follows:
.. clicmd:: show pony
Prints an ASCII pony. Example output:::
>>\.
/_ )`.
/ _)`^)`. _.---. _
(_,' \ `^-)"" `.\
| | \
\ / |
/ \ /.___.'\ (\ (_
< ,"|| \ |`. \`-'
\\ () )| )/
hjw |_>|> /_] //
/_] /_]
When documented this way, CLI commands can be cross referenced with the
:clicmd: inline markup like so:
:clicmd:`show pony`
This is very helpful for users who want to quickly remind themselves what a particular command does.
When documenting a cli that has a no form, please do not include the no
form. I.e. no show pony would not be documented anywhere. Since most
commands have no forms, users should be able to infer these or get help
from vtysh’s completions.
When documenting commands that have lots of possible variants, just document
the single command in summary rather than enumerating each possible variant.
E.g. for show pony [foo|bar], do not:
.. clicmd:: show pony
.. clicmd:: show pony foo
.. clicmd:: show pony bar
Do:
.. clicmd:: show pony [foo|bar]
Configuration Snippets
When putting blocks of example configuration please use the
.. code-block:: directive and specify frr as the highlighting language,
as in the following example. This will tell Sphinx to use a custom Pygments
lexer to highlight FRR configuration syntax.
.. code-block:: frr
!
! Example configuration file.
!
log file /tmp/log.log
service integrated-vtysh-config
!
ip route 1.2.3.0/24 reject
ipv6 route de:ea:db:ee:ff::/64 reject
!
Footnotes